BLOG
Test su Googlebot e url citate ma senza link
A inizio 2013 ho fatto un piccolo test per cercare di capire come si comportava il googlebot di fronte ad una url presente nel testo, ma solamente citata, quindi senza link (senza l’attributo a href).
Voglio condividere con voi i risultati di questo mio test. Ovviamente non si possono trarre conclusioni definitive visto che è un test limitato, ma chiunque può replicarlo facilmente per approfondire l’argomento. Prendetelo come uno spunto di riflessione o di approfondimento.
Ho testato varie tipologie di url citate, quindi il test è stato diviso in varie parti.
Test 1. Citata url di pagina che non esiste
06/02/2013 inserita nella home citazione ad una pagina che non esiste
Test: http://www.riccardoperini.com/questa-pagina-non-esiste.php
07/02/2013 Google prende in cache il nuovo testo della home in cui è presente la citazione.
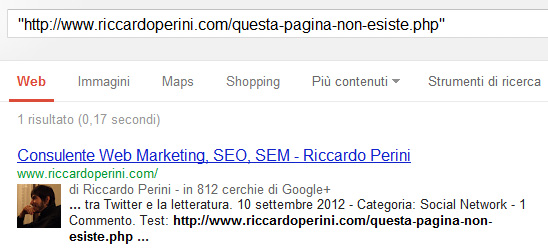
08/02/2013 la pagina viene richiesta dal googlebot e ottiene un 404
66.249.73.99 – – [08/Feb/2013:06:11:05 -0600] “GET /questa-pagina-non-esiste.php HTTP/1.1” 404 11415 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
Nei GWT in Salute > Errori di Scansione > Non trovato mostra la pagina, rilevata 08/02/2013 e come fonte del link indica “con link da: http://www.riccardoperini.com.

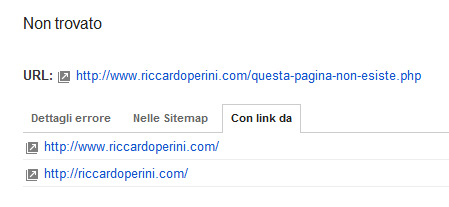
Il googlebot ha poi provato a richiedere nuovamente l’url un paio di volte nei mesi successivi, nonostante in data 09/03/2013 sia stato tolta la citazione dell’url in home.
Test 2. Citata url di pagina che esiste ma non è linkata
Il 15/02/2013 viene creata una pagina statica e pubblicata qui http://www.riccardoperini.com/questa-pagina-non-ha-link.php. Lo stesso giorno viene inserita una citazione della pagina nella home. In sostanza la pagina non viene inserita nella sitemap, non è mai stata visitata, non è linkata da nessuna parte, ma solo citata dalla homepage in questo modo:
Test 2: http://www.riccardoperini.com/questa-pagina-non-ha-link.php
Il 24/02/2013 il googlebot richiede la pagina:
66.249.73.99 – – [24/Feb/2013:22:58:19 -0600] “GET /questa-pagina-non-ha-link.php HTTP/1.1” 200 1241 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
Il 28/02/2013 la pagina è presente in SERP
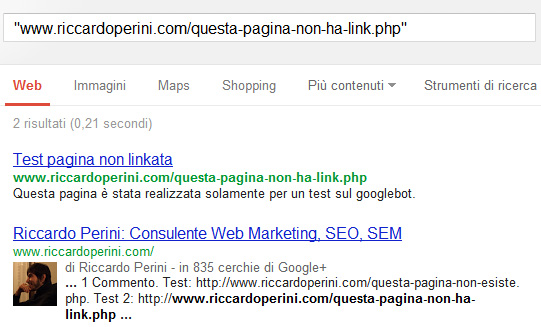
E compare ancora oggi (12/09/2013) per la ricerca [test pagina non linkata].
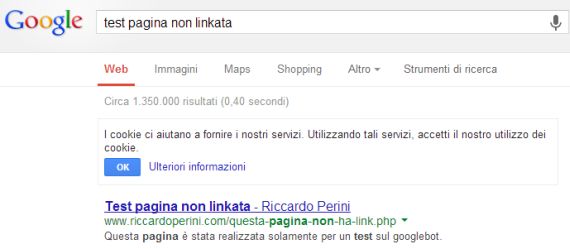
Il bot è ripassato poi anche nei mesi successivi, nonostante in data 09/03/2013 sia stata tolta la citazione dell’url in home.
Test 3 e 4. Url citata con www e con http://www
Il 09/05/2013 carico online una nuova pagina statica, questa volta senza codice Analytics installato. Anche questa volta non la visito, non la inserisco nella sitemap e non la linko da nessuna parte. Semplicemente aggiungo una citazione dalla homepage:
Test 3: http://www.riccardoperini.com/pagina-no-link-no-ga.php
Sempre il 09/05/2013 pubblico anche un’altra pagina con le stesse caratteristiche e la cito in homepage, ma senza http://, cioè così:
www.riccardoperini.com/pagina-citata-no-http-no-ga.php
Il 15/05/2013 il googlebot richiede entrambe le pagine:
66.249.73.71 – – [15/May/2013:15:23:40 -0500] “GET /pagina-citata-no-http-no-ga.php HTTP/1.1” 200 1206 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
66.249.73.71 – – [15/May/2013:15:24:28 -0500] “GET /pagina-no-link-no-ga.php HTTP/1.1” 200 1016 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
Il 16/05/2013 cercando l’url citata, Google la mostra nel testo della homepage.
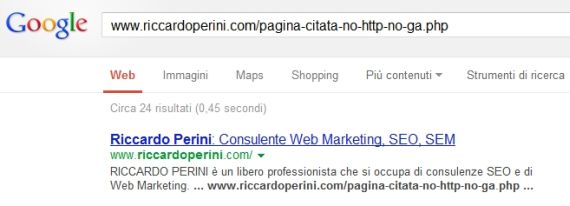
Il 17/05/2013 le due pagine compaiono in SERP ricercando le url con la funzione “site:”
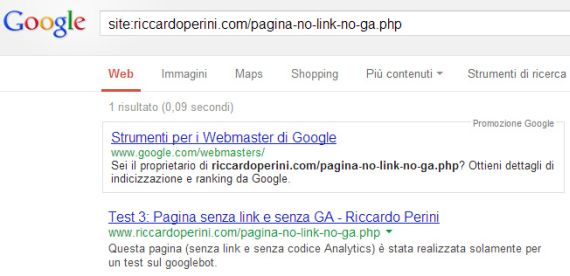
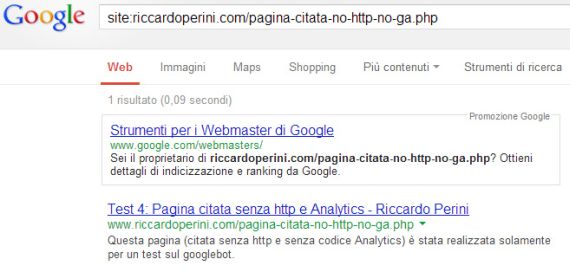
Il 04/06/2013 tolgo le citazioni delle due url nel testo della home e anche in questo caso, nei mesi successivi, il googlebot continua a richiedere le due url.
Test 5: url citata senza http://www
Il 04/06/2013 carico online una nuova pagina statica, ancora una volta senza codice Analytics installato. Anche questa volta non la visito, non la inserisco nella sitemap e non la linko da nessuna parte. Semplicemente aggiungo una citazione dalla homepage, ma senza http://www. La cito così:
RiccardoPerini.com/quattro
E nella stessa data aggiungo anche un’altra citazione ad una pagina inesistente:
RiccardoPerini.com/nonesisto
11/06/2013 compaiono nella cache della home le citazioni “RiccardoPerini.com/quattro” e “RiccardoPerini.com/nonesisto”
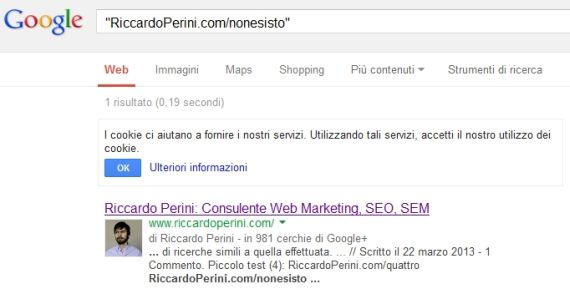
Il 12/09/2013 tolgo le citazioni in home. Fino ad oggi queste due url citate senza http:// e senza www non sono mai state richieste dal googlebot.
——-
La Conferma di John Mueller (06/09/2013)
John Mueller, durante l’hangout del 06/09/2013 (al minuto 47) ha confermato che Google utilizza anche le url solo citate (quindi senza l’attributo a href) come fonte per scoprire nuove pagine di contenuto.
Ecco la trascrizione di quanto detto da John Mueller nell’hangount del 6 settembre 2013.
Domanda: “Does Google respect an url or domain without a-tag in the content, as citation?”
Risposta di John Mueller: Without any kind of “a href” link in the content, essentially we use those kinds of links to try to discover new content. So for instance if we see that someone has been writing about a new domain name and we can recognize that as a domain name in the text even without a normal HTML link there, then that is something where we will try to pick that domain name up, try to crawl it and index it and see if that is something worth including in our search results. […] Sometimes it happens that we pick up a whole URL like that. Sometimes we get it right. Sometimes someone will try to shorter a URL just linke dot-dot-dot in between and we try to crawl that URL so we get it wrong. But our goal here isn’t necessarily to pass any PageRank, which we don’t do with those kinds of links, but rather discover new URLs that we haven’t seen before. And if we see someone write about a URL that we haven’t seen before we will pick that up and try to index that for search.

Riccardo Perini
SEO Specialist dal 2004, aiuto le aziende a farsi trovare tra i risultati organici di Google.
Data pubblicazione: 12 Settembre 2013
Categoria: Motori di Ricerca, SEO
Tag: Test SEO

Ciao Riccardo,
test molto interessante, magari fossero tutti così i post seo. La questione del caching in realtà prescinde dalle richieste dei bot, in quanto Google mostra in cache contenuti testuali e in questo caso riprende quanto indicizzato e digitato da te nella query. Interessante però il resto, e come in assenza del prefisso www la richiesta non avvenga.
Ora sarebbe utile capire come Google si comporti in riferimento ai brand name non linkati presenti in un testo, in termini di co-citazioni.
Domanda: quale strumento hai usato per il crawl rate test?
Ciao Dario,
ti ringrazio :)
Tieni presente però che è solo un piccolo test, sicuramente non esaustivo. Sarebbe da replicare su larga scala.
Inoltre io qui ho considerato solo i link interni, mentre in effetti sarebbe interessante approfondire il discorso della co-citazione.
Ho analizzato i file di log.
E’ interessante avere la controprova dei test che pubblicai in febbraio, dove segnalavo:
1 – google legge le url senza link
2 – google indicizza anche con robots.txt
Ora è la prova del 9, almeno per il punto 1!
Grazie.
ps: metti la notifica dei nuovi commenti in questo povero blog! ;)
Per chi vuole approfondire, l’atro test di cui parla merlinox lo trovate qui: http://blog.merlinox.com/testseo-robots-e-bot/
PS: si, la notifica prima o poi la aggiungerò :)
La spiegazione secondo me è semplice:
parsando la pagina e recuperando il codice, un link href o un link testuale, apparirebbero comunque come 2 link da tenere in considerazione
Anzi, per certi versi, sarei tentato da tenere in considerazione il link citato invece del linkbuilding mediante il link href (da testare)
Lo avevo notato qualche tempo fa e volevo conferma :)